11.2 Nlp中的微调
- Nlp中不存在大规模的标准数据
- 有大量未标注文档
- 自监督预训练
- 产生伪标号
- Nlp常见任务
- LM(大语言模型):预测下一个单词
- MLM(掩码的大语言模型):完形填空
- 常见预训练模型
- 词嵌入:学习两个嵌入uw和vw(对于每个单词w)

- 训练的时候学习每个词的uw和vw,如果两个词的uw和vw内积很大说明相似度较高
- 预测的时候把邻近的词的vw和预测的词的uw做内积,哪个预测的词的内积高说明就是它
- 基于transformer的预训练模型:
- bert:使用transformer的encoder
- 模型架构
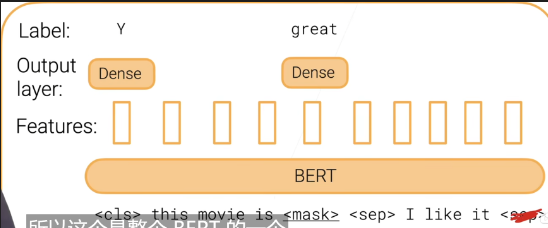
- 微调
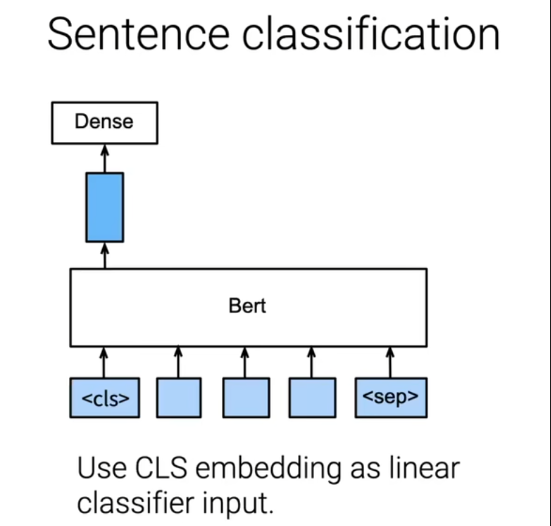
- 语句分类:分类任务,对于cls的输出层拿到label
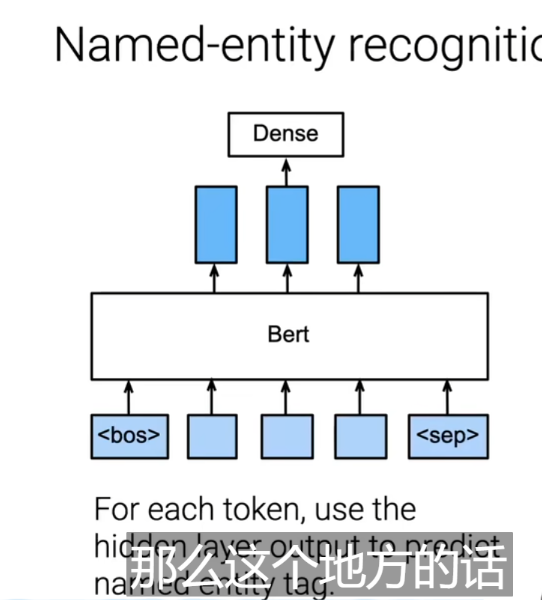
- 实体检测:每个词的输出层都需要检测是否是实体
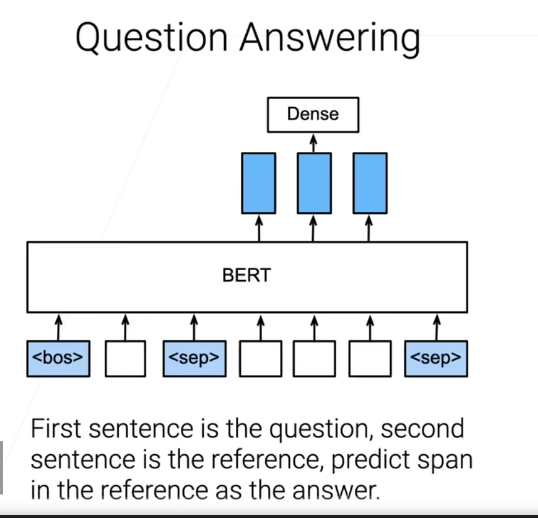
- 问题回答:对于上下文信息,判断哪个地方是答案的开始
- Gpt:使用transformer的decoder
- T5:使用transformer的encoder-decoder结构
- 哪里找transformer预训练模型?
- 如何用预训练模型训练?
- tokenizer根据每个模型会不一样,每个模型有不同的切词的方法。如果选择了不同模型的tokenizer,字典会对应不上;还需要vocabulary.txt,把tokenizer之后的字符对应成数组序号。(对比CNN,对图像的处理不需要tokenizer,因为图像的像素都是一个个实数值)11.1 CV中的微调
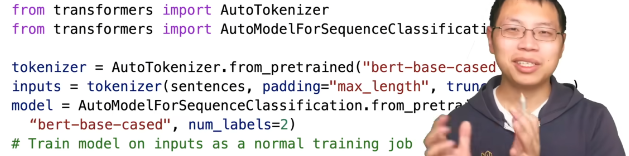
- padding是和bert有关的,默认是512,作为输入层。如果输入少于512,补全;如果多,切割
References
11.2 NLP中的微调【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili